









「探究学習をやってみよう(その2):CNN+5MLs(5つの機械学習)」の探究活動
皆さん、こんにちは。テラオカ電子です。いきなりですが「MNIST」をご存じですか?機械学習やAIについて勉強したことがある方は、聞いたことがあるかもしれません。MNISTというのは、手書き数字のデータセットで、機械学習の入門としてよく使われるものです。
【「MNIST」の紹介サイトはこちらから】

今回は、機械学習導入の鉄板である「MNIST」を使って探究を行います。前回(第30回ブログ記事)同様に、プログラムを提供しますので、試して頂き、そして、面白かったらご自身の興味でアレンジして探究を楽しんでください。
高校生の皆さんは、普段、授業でノートを取ったり、テストに回答したりする際、手書きがほとんどだと思いますが、今では、(私を含めて)仕事では、ほとんど手書きはなくなりました。それでも、冠婚葬祭や年賀状では、まだ手書きは健在ですね。なにより、その人自身の温かみを感じます。また、個性もあります(人格まで表しいているという人もいますが、そこまで言えるかどうかは分りません)。
なので、この個性的な手書き文字を機械(コンピュータ)が読み取ることは、これまで難しさがありました(人間ならば容易に読むこともできるし、その人の個性までも読み取れますが)。しかし、近年では、機械学習(統計的手法)やディープラーニング(深層学習)の進歩により精度よく読み取ることができます。
そこで、今回は、その基礎技術である、画像認識でブレークスルーを起こしたCNN(畳み込みニューラルネットワーク)と統計的な機械学習(5種類)を使って、手書き数字の分類を行います。
今回、なぜ機械学習を5種類も扱うのかというと、機械学習にはそれぞれ得意、不得意があるからです。一番性能が良いものを使えばそれで良いという考え方もありますが、性能は、画像の種類によっても、また実用上の扱い易さによっても変わってきますので、簡単に決めることができません。それに、ここが大事なのですが、これから皆さんが、ご自身の課題を解決していくとき、一つの方法だけしか知らないのでは応用が利きません。様々な手法の原理を理解していることが、新たな発見に繋がりやすいのです。ニュートンが、論敵のロバート・フックに宛てた書簡の中で、「巨人の肩の上に立つ」と述べていますが、研究(探究)での新たな知見は、過去の積み上げから得られるものだからです。ぜひ、古いと言わずに、各自でそれぞれの機械学習について調べてみてください。
今回もプログラムは、pythonです。、このpythonプログラムは、Google Colaboratory上で動作させます。なのでGoogleのアカウント(無料)が必要になります。
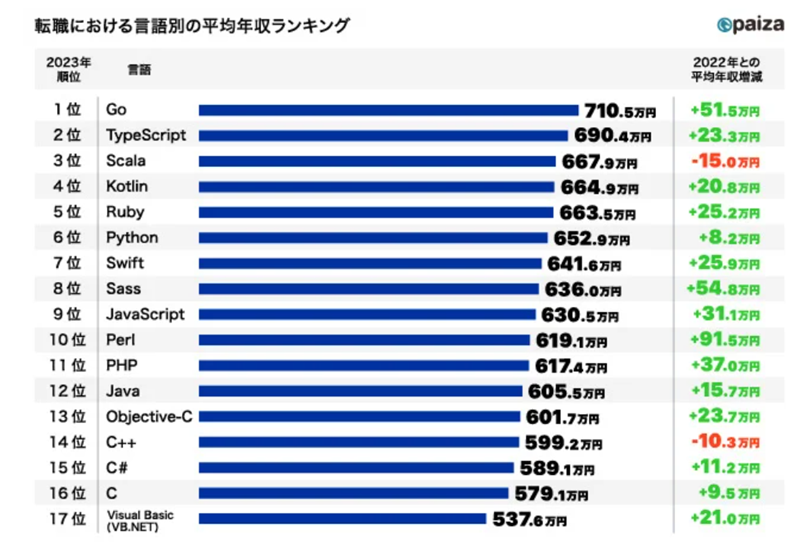

ところで、どのプログラム言語が年収に繋がるのかについて、上記のような調査結果があります。これからいくと、年収を上げるには、一位の「Go」を勉強するのが一番効率的と言えますが、実際は、それほど単純ではありません。なぜなら「Go」は初心者には難しいので、「python」や「Java」、「C」を熟知したエンジニアが使っていることが多いのです。なので、この結果はプログラムの上級者が「Go」を使って業務を行っていることを示しているに過ぎないかもしれません。
横道にそれましたが、「pythonは、サーバサイド言語としてシステム管理やツール・アプリケーション開発、科学技術計算、Webシステムなどで広く利用されています。特に、2010年代ごろからの機械学習ブームでは、優れた科学技術計算ツールとして評価され、大きな人気を得ています。またpythonは「読みやすさ・分かりやすさ」を重視した言語で、初学者でも学びやすく、社会人、学生ともに人気です。」とありますので、高校生の皆さんは、迷わずpythonから始めて問題はありません。今回の探究学習を通して、pythonにも慣れてもらえればと思います。
では、前置きはこれくらいにして、探究学習を始めましょう。
【1今回の探究学習の概要】
はじめに、今回取り組んでいただく探究学習の概要を説明します。
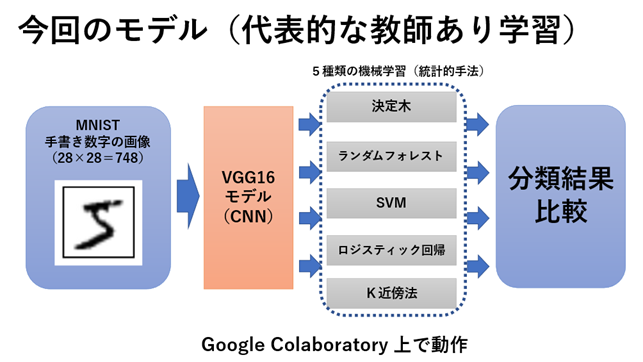
今回扱う機械学習のモデルを上記に示します。
まず、手書き数字の画像データセットである「MNIST」をダウンロードします。それをCNN(畳み込みニューラルネットワーク)であるVGG16モデルで画像テータを変換します。
MNISTの画像データは、28*28(=784次元)ピクセルの白黒画像です。これをVGG16を通すことにより512次元に圧縮します。784次元から512次元にするので、情報が少なくなって大丈夫なのかと心配になるかと思いますが、VGG16はCNNなので、画像の特徴を捉えることができます。したがって密な情報に変換されたことになります。この点が気になる方は、VGG16モデルを介さずに直接機械学習を行った場合と比較する探究も面白いと思います。
VGG16というのは,「ImageNet」と呼ばれる大規模画像データセットで学習された16層からなるCNNモデルです。Oxford大学の研究グループが提案し2014年のILSVRで好成績を収めました。16層からなるCNNモデルには、(224×224)の入力サイズのカラーチャネルの入力層と1000クラス分類の出力層を含み様々な研究に使用されています。
ところで、生物の進化の過程において、「カンブリア爆発」(ChatGPTの説明は後述)というのがあります。そこでは、「目」の獲得が生物の多様性を促進したと考えられています。ここで扱うCNNは、機械に「目」を持たせることが可能にしたと言われています。このCNNの実用化は、Web上のビッグデータ活用の「AIの進化」の起点になりました。
【「VGG16モデル」の紹介サイトはこちらから】

【「カンブリア爆発」についてのChatGPTの説明】
カンブリア爆発は、地球上で最初の多細胞生物が急速に進化した時期を指します。約5億4,000万年前のカンブリア紀初期に起こったこの進化の急速な爆発的出来事は、地球上で最初の複雑な動物が出現した時期として知られています。
この時期には、多様な動物の体型や構造が現れ、それまでの地球上の生物相とは大きく異なる形態が登場しました。カンブリア爆発の最も注目すべき特徴の一つは、多細胞生物が異なる形態の器官を発達させ始めたことです。その中で、「目」の進化は特に重要です。
カンブリア爆発によって、「目」は複眼や単眼といったさまざまな形態で登場しました。これは視覚の進化における重要な一歩であり、生物が環境を感知し、捕食や避けるための新しい戦略を発展させるのに役立ちました。
「目」の進化は、生物が環境の情報を収集し、それに応じて行動する能力を向上させたことを意味します。これにより、生物の捕食や防御の能力が向上し、さらに生態系の複雑性が増大しました。また、「目」の進化は、生物の行動パターンや生態系の相互作用にも影響を与え、進化の多様性を促進しました。
カンブリア爆発は、地球上の生物進化の歴史における重要な出来事の一つであり、多細胞生物が多様な形態や機能を発展させる上での重要なマイルストーンです。「目」の進化は、生物の進化と適応のプロセスにおいて中心的な役割を果たし、生物の多様性と複雑性の基盤を築くのに貢献しました。
次に、VGG16モデルからの出力データ(512次元)を5つの統計的機械学習モデルに与えます。そして、それぞれの機械学習モデルで学習させたのち、MNISTの画像を分類させます。
今回は、5つの機械学習モデルとして、「決定木」、「ランダムフォレスト」、「SVM(サポートベクターマシン)」、「ロジスティック回帰」と「k-NN(k近傍法)」を扱います。
それぞれのモデルについては、参考サイトを紹介しますので各自で調べてください。ここでは、簡単にそれぞれのモデルの特徴と利点を紹介します。
1.決定木:
決定木は、データを分類や回帰するための木構造を用いるモデルです。今回は分類(手書き数字を0~9に分類)を行います。木構造の各ノード(枝分かれの元)は特定の特徴量(今回はVGG16の出力の512次元データ)でデータを分割し、その結果に基づいて分岐が進みます。最終的には葉ノード(最終的な分類)で結果が出力されます。利点としては、 直感的に理解しやすく、可視化が容易です。また、特徴量のスケールに影響を受けにくいがあります。
【「決定木」の解説サイトはこちらから】
2.ランダムフォレスト:
ランダムフォレストは、複数の決定木を組み合わせたアンサンブル学習(データを任意にサンプルして決定木を複数作ります。それら複数の決定木の結果の多数決をとる)の手法です。その結果より汎化性能の高いモデルを構築できます。利点としては、過学習(学習データに特化して学習すること)に強く、高い汎化性能を持ちます。また、特徴量の重要度を評価することもできます。
【「ランダムフォレスト」の解説サイトはこちらから】

3.SVM(サポートベクターマシン):
SVMは、2つのクラスを分離する最適な境界線(超平面)を見つけるための手法です(今回は多クラス分類なので、組合せが複数になります)。マージン(2つのクラスの境界領域の幅)を最大化する境界線を見つけることで、汎化性能が向上します。利点としては、高次元のデータや非線形なデータにも適用可能であり、カーネルトリック(座標変換すること)を使用して複雑な関係をモデル化できます。
【「SVM(サポートベクターマシン)」の解説サイトはこちらから】

4.ロジスティック回帰(分類):
ロジスティック回帰は、2つのクラスを分類するためのモデルです(回帰とありますが分類です)。入力変数の線形結合をロジスティック関数に通し、その結果を確率として解釈し、閾値に基づいてクラスを予測します(今回は閾値をデフォルトのままにしています。深く分析したい場合は、各自で調べて変えてください)。利点としては、結果を確率として出力するため、クラスの不確実性を考慮できます。また、計算が比較的高速です。
【「ロジスティック回帰」の解説サイトはこちらから】

5.k-NN(k近傍法):
k-NNは、新しいデータポイントを分類する際に、最も近いk個のトレーニングデータポイントを参照し、それらの多数決によってクラスを決定します。利点としては、単純で理解しやすく、ハイパーパラメータの調整が比較的簡単です。また、非線形な決定境界もモデル化できます。
【「k-NN(k近傍法)」の解説サイトはこちらから】

これら5つの手書き数字の判定結果(正解率)を比較しましょう。また学習にかかった時間も比較してみましょう。さらに、各学習モデルのハイパーパラメータも調整してみましょう。
最後に、ただ判定するだけでは面白くありませんので、実際の紙に数字を描いてみて、それをカメラで読み込ませて判定させてみます。USBのWebカメラがあれば便利です。
冒頭でも述べましたが、今回は、機械学習の入門である「MNISTの画像」を扱います。また、5つの古典的な機械学習を使います。ただし、これが現在のAIだと勘違いされては困りますので、最近の技術(2020年ですが)についても理解を深めてもらえればと思います。参考に「STEAMライブラリ」の「AI活用人材育成講座(理論講座)」から2つ紹介しておきますので、ぜひご視聴ください。
【「AI活用人材育成講座(理論講座)」【layer2】画像・映像・3次元データを扱うAIの導入】
また、今回の探究学習とほぼ同じことを実行した動画をYouTubeでアップしています。こちらも参考にしてください。
【テラオカ電子:「「転移学習 VGG16+いろいろ Google Colaboratory編」をつくりました。」はこちらから】
では、前提知識はこれくらいにして、実際に動かしてみましょう。
【2研究の問い:テーマを決めよう】
今回の探究のテーマは、「画像分類が5つの機械学習のモデルでどの程度可能なのか?」です。もちろん、ご自身で一通り実行した後、オリジナルな問いやテーマを決めてください。そして、その問いの答えを見つけるために、プログラムを変更して実行させてみましょう。
MNISTではなく違う画像でやるとか、CNNモデルの構造を変更したり、使わなかったり、また、今回の5つ以外の機械学習モデルで試してみるなどしてください。面白い結果など出ましたら教えてください。それでは、いよいよ準備に入りましょう。
【3準備】
- 私のGitHubのリポジトリからプログラムをダウンロードしよう。
「Code」ボタンからプルダウン表示させて、ZIPファイルをダウンロードします。
【私のGitHubのリポジトリのURL】

- Google Driveにファイルをアップロードしよう。
Googleのアカウントが必要です。MyDriveに自分でフォルダ(名前は自分で決めてください)を作り、そこに①でダウンロードしたファイルをアップロードします。下図のようになればOKです。
私の場合は、「CNN+5MLs」のフォルダの下にアップロードしました。
以上で、準備は完了です。次は、いよいよプログラムを走らせます。
【4プログラムの動作】
- 「MNIST_CNN_5MLs_ver1.ipynb」をダブルクリックしてGoogle Colaboratoryを立ち上げよう。
右クリックで「アプリで開く」からでもOKです。
【「Google Colaboratory」の使い方はこちらを参考にしてください】

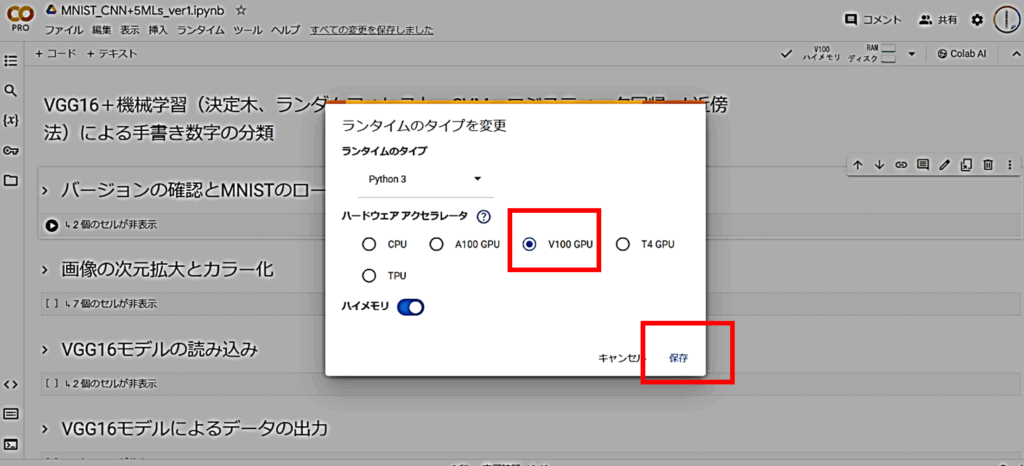
- ランタイムのタイプをGPUに変更しよう。
メニューの「ランタイム」をクリックして、さらにプルダウン表示の「ランタイムのタイプの変更」をクリニックします。下図のようなウインドウが表示されたら「GPU」を選択して、「保存」をクリックします(私の場合、「有料版」ですが、「無料版」でも同様に「GPU」を選択してください)。
今回、学習に時間がかかりますので「CPU」ではなく「GPU」を使います。もちろん「CPU」でもできます。
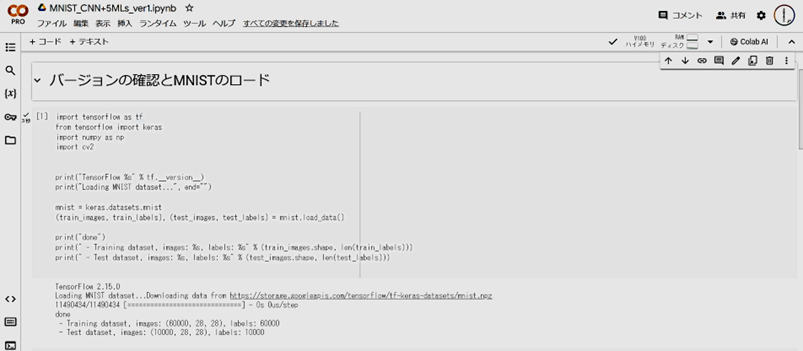
- コードセルの左の三角ボタン(赤○で示した場所)を順にクリックしていきます。
実行したいセルを選択してSHIFT + ENTER でもOKです。下図は、三角ボタンを押した後の状態です。MNIST画像がダウンロードできました。
以下、順に実行ボタンをクリックしていくだけです。一つずつクリックするのが面倒な方は、メニュータブの「ランタイム」の「すべてのセルを実行」をクリックしてください。
【5結果と考察】
- MNISTの画像をダウンロードしたあと、「画像の次元拡大とカラー化」を行います。これは、MNISTが28*28ピクセルのモノクロ画像であるのに対し、VGG16モデルの入力が56*56次元以上かつカラー画像でないといけないためです。学習データ(train)60000枚とテストデータ(test)10000枚それぞれを変換します。その後、学習データの最初の10枚の画像を表示させています。
- 次に、「VGG16モデルの読み込み」を行います。この時、パラメータは固定(学習しない)としています。そして、読み込んだモデルの出力を1次元にする層を加えます。
- 次に、学習データとテストデータを規格化(255で割って0~1の範囲のデータにする)して、それを先ほどのVGG16モデルに入力し、学習データ、テストデータのそれぞれの出力をつくります。
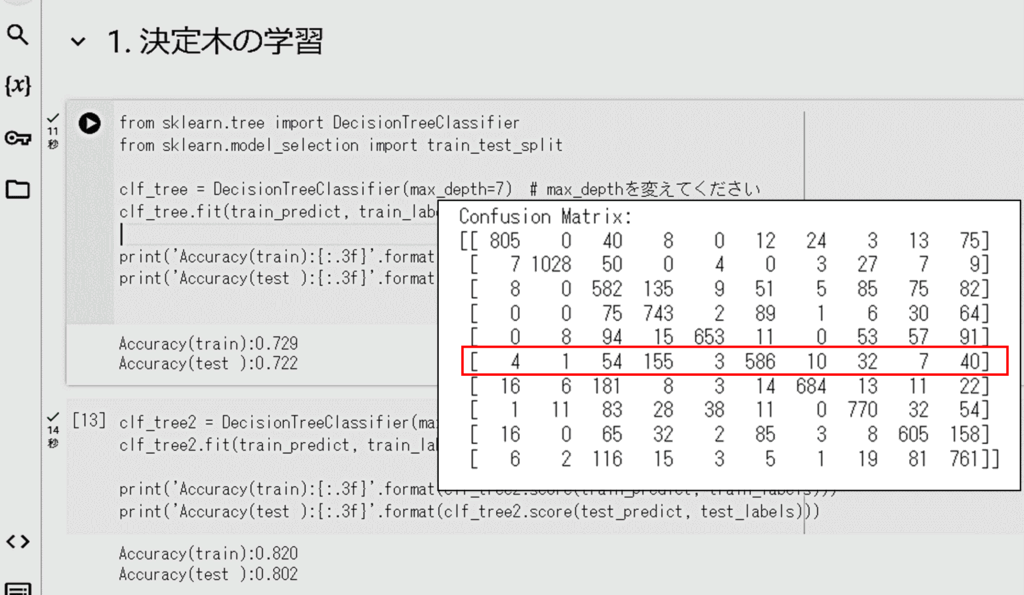
- 次に「1.決定木の学習」を行います。葉の深さを7と10として学習データで学習させ、学習データとテストデータの判定結果を計算しています。葉の深さが7の時は、学習データとテストデータの正解率(Accuracy)に差はありませんでしたが、葉の深さを10にすると、正解率は上がりますが、学習データよりもテストデータの正解率が下がりましたので、過学習が起こりました。その後、分類結果の評価(精度、再現率、F1スコアのメトリック)と可視化(混同行列)を計算しています。混同行列(Confusion Matrix)の結果から、例えば「5」は、「3」と間違うことが多いことがわかります(混同行列は、各行が実際のクラスを示し、各列が予測されたクラスを示しています)。
ここで、「過学習」についてChatGPTの説明を引用しておきます。詳細は、各自で調べてください。
機械学習における「過学習(Overfitting)」は、モデルが訓練データに過度に適合し、訓練データに含まれるノイズやランダムな変動まで捉えてしまう現象です。これにより、訓練データには非常に高い性能を示しますが、新しいデータに対しては一般化性能が低下してしまう問題が生じます。
具体的には、過学習が起こると、モデルが訓練データに極端に適合し、訓練データ内の特定のパターンやノイズにまでフィットしようとします。これにより、モデルは訓練データ内の微細な変動やノイズに敏感になり、新しいデータに対してはうまく汎化できなくなります。
例えば、簡単な線形回帰の場合を考えてみましょう。訓練データが一次関数に従う場合、過学習が起きると、モデルが訓練データの各点に完全にフィットしようとします。つまり、訓練データに含まれるノイズまで学習してしまうことになります。その結果、訓練データ内では非常に良い結果が得られますが、新しいデータに適用すると、モデルが過剰に複雑であるため、うまく汎化されない可能性が高くなります。
過学習を回避するためには、いくつかの方法があります。まず、より多くの訓練データを使うことが重要です。また、モデルの複雑さを調整することも有効です。たとえば、ニューラルネットワークの場合、層の数やユニットの数を制限することで、過学習を防ぐことができます。さらに、正則化やドロップアウトなどのテクニックを使うことも効果的です。これらの手法を使うことで、モデルが訓練データにのみ適合することなく、一般化性能を向上させることができます。
【「過学習」を解説するサイトはこちらから】

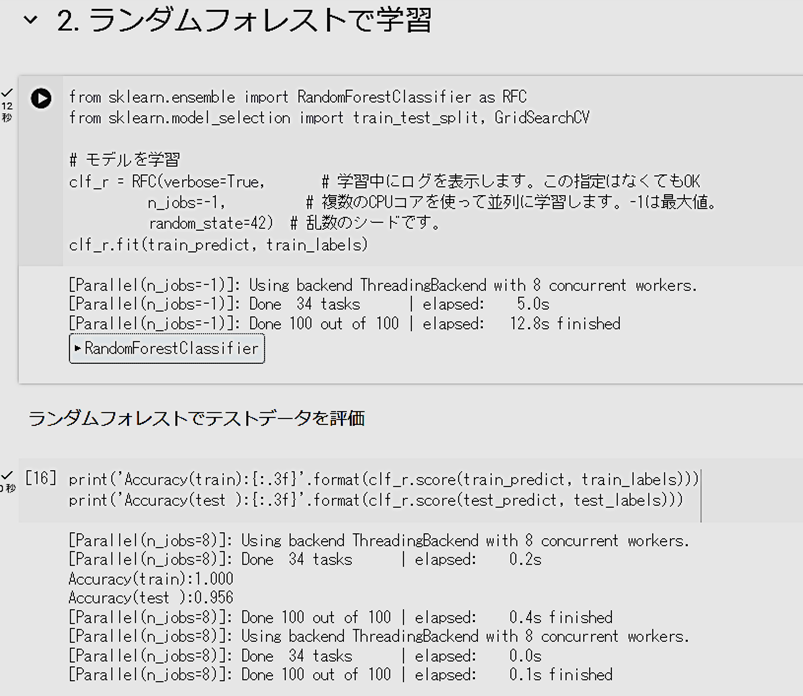
- 次に「2. ランダムフォレストで学習」を行います。過学習を少し起こしていますが、テストデータの正解率は、0.956まで上がりました。
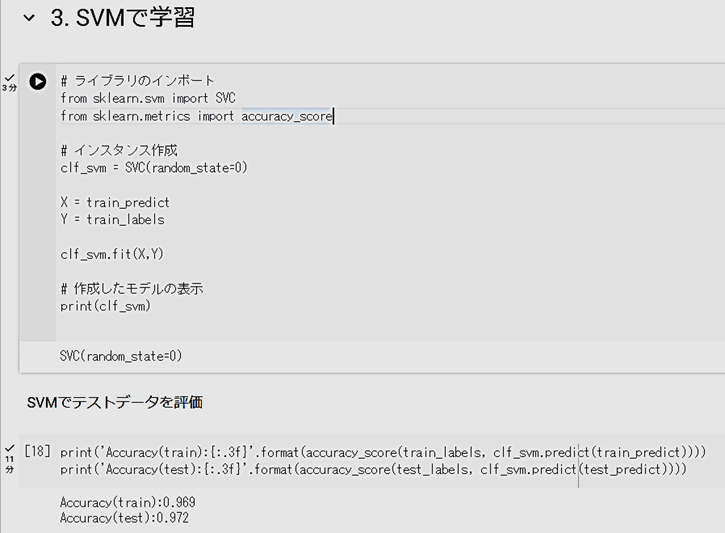
- 次に、「3. SVMで学習」を行います。この学習には少し時間がかかります。過学習はそれほど見られず、テストデータの正解率は、0.972まで上がりました。
- 次に、「4. ロジスティック回帰で学習」を行います。過学習はそれほど見られず、テストデータの正解率は、さらに0.975まで上がりました。

- 次に、「5. k近傍法で学習」を行います。近傍範囲は7にしています。いろいろ変えて試してください。過学習が少し見られ、テストデータの正解率は、0.966でした。

- 最後に、⑧「5. k近傍法で学習」で学習したモデルを使って、実際の手書き数字を分類します。プログラムは、カメラで撮影した画像の輪郭を抽出した後、明暗を2値に反転させています(x1 = np.where(x1 >= 100, 5, 250))。これは、手書き数字の文字が黒であるためと、中間調が上手く撮影できないと考えたからです。以下に実際の手書き数字を描いて試した判定結果(「0」から「9」)を示します。


輪郭が2重に抽出しているところもありますが、現実の手書き文字の分類は、学習データと様々な条件が異なりますので、上手くいきません。こうした問題の改善を探究することも面白いと思います。
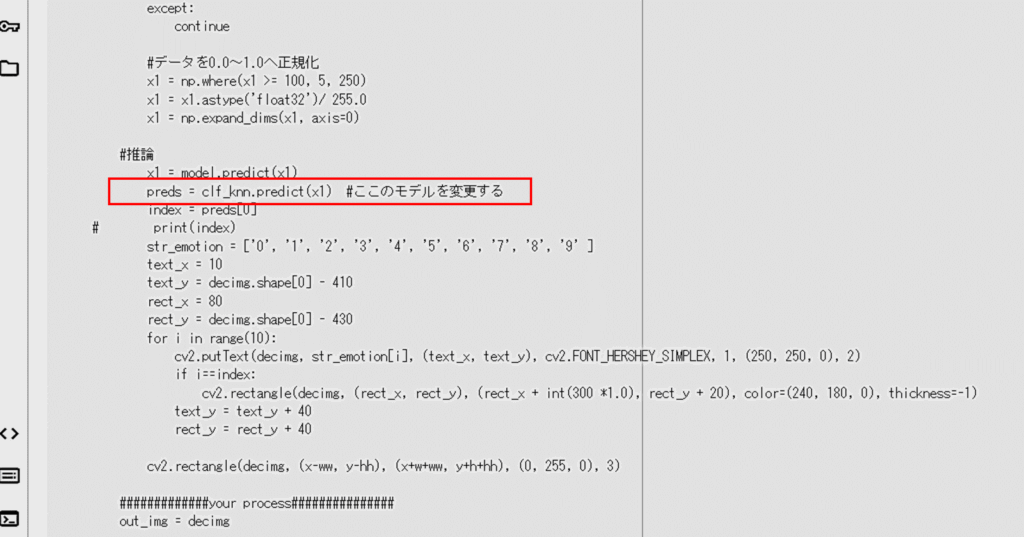
なお、他のモデルで試したい場合は、以下で示すコードのところを、それぞれのモデルに書き換えればOKです。こちらも試してください。
具体的には、preds = clf_knn.predict(x1) のところで、clf_knn を変更します。
【6まとめ】
今回は、MNISTという手書き数字の画像データを機械学習を使って分類することを行いました。機械学習のモデルとして、まずCNNを使って画像の特徴を捉え、それを5つの機械学習モデルで分類させました。その結果、ロジスティック回帰では、テストデータの分類正解率を0.975まで上げることができました。ハイパーパラメータのチューニングを行えばさらに向上できそうです。
また、実際に手書きで数字を書いて、それをカメラで読み込み判定させることも行いました。しかしながら、うまくいかない場合もあることが分かりました。実際の手書き数字の画像が、学習データの画像と異なるためだと思います。これについても改善することは面白いと思います。
今回使った機械学習のモデルは、古典的なものでした。ニューラルネットワークを使えばもっとうまくできるかもしれません。しかしながら、古典的でシンプルなものでも工夫することで高い精度が実現できることもあります。また、こうした古典技術のアイディアの要素が、先端技術のブレークスルーになることもありますので、しっかり押さえておくことは重要だと考えます。
面白い分析ができましたら、本サイト(CQゼミ)の「問い合わせ」から教えてください。また、プログラムが動かなかったり、何かトラブルがあったりしたら、教えてください。直ぐには、返信できませんが、対応していきます。
ここまで読んでくれて、ありがとうございます。
テラオカ電子
【イチオシのYouTube動画】
このコーナでは、記事に関連する(関連しないかもしれません)気になるYouTube動画を紹介しています。今回の探究学習では、5つの機械学習を扱いました。そこで、「5」繋がりで、かつて日本テレビ系で放映された「FiVE」の主題歌であったMOON CHILD の『ESCAPE』(1997)を紹介します。私はこのドラマを最初の2、3回しか見ていないので、結末がどうなったか今でも気になっています。5人の人気若手女優さんたちが出演されていたのですが、ドラマの展開が奇抜で面白かったです。この曲を聴くと、今でもその場面を思い出します。カラオケで歌えたら最高なんですが・・・音痴なので歌えないのが残念です。
「MOON CHILD / ESCAPE」
【2024/03/29投稿】







